딥러닝 + 알츠하이머 진단
질문: 딥러닝은 뇌 영상이미지로 알츠하이머병 환자를 얼마나 정확히 구분할 수 있을까?
논문의 결과: 엄선된 16개의 논문을 세밀히 비교해본 결과 여러 종류의 신경 영상과 바이오마커를 결합해서 딥러닝을 적용했을때 98.8%의 분류 정확도를 보였습니다.
딥러닝을 이용한 알츠하이머 병의 진단
딥 러닝은 그동안 컴퓨터 비전 영역에서 복잡한 고차원 데이터의 구조를 식별하는 데 있어서 기존 기계 학습보다 뛰어난 성능을 보여주었습니다. 특히 최근 영상 의학 기술의 급속한 발전으로 대규모 의 신경 영상 데이터가 생성됨에 따라 알츠하이머병의 조기 진단 및 뇌 영상 이미지의 자동 분류에 딥 러닝을 적용하기 위한 노력이 계속되었습니다.
이 포스팅은 알츠하이머병의 진단을 위해 신경 영상 데이터에 딥러닝을 적용한 논문을 전수 조사한 “Deep learning in Alzheimer’s disease: diagnostic classification and prognostic prediction using neuroimaging data” Frontiers in aging neuroscience” (2019) 논문을 옮긴 것입니다.
논문 인용 하기
Jo, Taeho, Kwangsik Nho, and Andrew J. Saykin. "Deep learning in Alzheimer's disease: diagnostic classification and prognostic prediction using neuroimaging data." Frontiers in aging neuroscience 11 (2019): 220.
2013년 1월부터 2018년 7월 사이에 발표된 알츠하이머병에 대한 딥러닝 논문을 PubMed와 Google Scholar 를 사용해 검색했고 총 358개의 검색 결과 중 자체적으로 세운 기준을 충족하는 연구는 총 16개의 논문을 상세 검사 대상으로 정했습니다. 16개 논문중 4개는 딥 러닝과 기존 머신 러닝 접근 방식의 조합을 사용했고 12개는 딥 러닝 접근 방식만 사용했습니다. 기존의 기계 학습법과 스택형 오토 인코더(SAE)의 조합은 알츠하이머병 분류의 경우 최대 98.8%의 정확도를 보였고, 알츠하이머병의 전 단계인 경도인지 장애(MCI)로부터 알츠하이머병으로의 변환 예측 정확도는 83.7%였습니다.
SAE 방법은 feature를 선택하기 위한 사전 처리에 해당합니다. 이러한 과정 없이 신경 영상 데이터를 사용하는 CNN(Convolutional Neural Network) 또는 RNN(Recurrent Neural Network)과 같은 딥 러닝 접근 방식은 알츠하이머병 분류의 경우 최대 96.0%, MCI 변환 예측의 경우 84.2%의 정확도를 보였습니다.
여러가지 종류의 신경 영상과 바이오마커를 결합할 때 가장 높은 분류 정확도를 얻었습니다. 딥러닝 접근 방식의 성능은 시간이 지나면서 계속해서 향상되었고, 특히 여러 종류의 신경 영상 데이터를 사용하여 알츠하이머병 진단을 분류할 때 더 많은 가능성이 열려 있습니다.
딥 러닝을 사용하는 알츠하이머병 연구는 여전히 진화하고 있으며 omics 데이터등 추가 데이터를 통합하여 성능을 개선할 필요가 있어 보였습니다. 특정 질병 관련 기능 및 메커니즘에 대한 지식을 추가하는 것과, 설명 가능한 접근 방식으로 투명성을 높이는 과정도 필요해 보였습니다.
Deep learning in Alzheimer’s disease: diagnostic classification and prognostic prediction using neuroimaging data
Taeho Jo*, Kwangsik Nho and Andrew J. Saykin
Abstract
Deep learning, a state-of-the-art machine learning approach, has shown outstanding performance over traditional machine learning in identifying intricate structures in complex high-dimensional data, especially in the domain of computer vision. The application of deep learning to early detection and automated classification of Alzheimer’s disease (AD) has recently gained considerable attention, as rapid progress in neuroimaging techniques has generated large-scale multimodal neuroimaging data. A systematic review of publications using deep learning approaches and neuroimaging data for diagnostic classification of AD was performed. A PubMed and Google Scholar search was used to identify deep learning papers on AD published between January 2013 and July 2018. These papers were reviewed, evaluated, and classified by algorithm and neuroimaging type, and the findings were summarized. Of 16 studies meeting full inclusion criteria, 4 used a combination of deep learning and traditional machine learning approaches, and 12 used only deep learning approaches. The combination of traditional machine learning for classification and stacked auto-encoder (SAE) for feature selection produced accuracies of up to 98.8% for AD classification and 83.7% for prediction of conversion from mild cognitive impairment (MCI), a prodromal stage of AD, to AD. Deep learning approaches, such as convolutional neural network (CNN) or recurrent neural network (RNN), that use neuroimaging data without pre-processing for feature selection have yielded accuracies of up to 96.0% for AD classification and 84.2% for MCI conversion prediction. The best classification performance was obtained when multimodal neuroimaging and fluid biomarkers were combined. Deep learning approaches continue to improve in performance and appear to hold promise for diagnostic classification of AD using multimodal neuroimaging data. AD research that uses deep learning is still evolving, improving performance by incorporating additional hybrid data types, such as—omics data, increasing transparency with explainable approaches that add knowledge of specific disease-related features and mechanisms.
Introduction
Alzheimer’s disease (AD), the most common form of dementia, is a major challenge for healthcare in the twenty-first century. An estimated 5.5 million people aged 65 and older are living with AD, and AD is the sixth-leading cause of death in the United States. The global cost of managing AD, including medical, social welfare, and salary loss to the patients’ families, was $277 billion in 2018 in the United States, heavily impacting the overall economy and stressing the U.S. health care system (Alzheimer’s Association, 2018). AD is an irreversible, progressive brain disorder marked by a decline in cognitive functioning with no validated disease modifying treatment (De strooper and Karran, 2016). Thus, a great deal of effort has been made to develop strategies for early detection, especially at pre-symptomatic stages in order to slow or prevent disease progression (Galvin, 2017; Schelke et al., 2018). In particular, advanced neuroimaging techniques, such as magnetic resonance imaging (MRI) and positron emission tomography (PET), have been developed and used to identify AD-related structural and molecular biomarkers (Veitch et al., 2019). Rapid progress in neuroimaging techniques has made it challenging to integrate large-scale, high dimensional multimodal neuroimaging data. Therefore, interest has grown rapidly in computer-aided machine learning approaches for integrative analysis. Well-known pattern analysis methods, such as linear discriminant analysis (LDA), linear program boosting method (LPBM), logistic regression (LR), support vector machine (SVM), and support vector machine-recursive feature elimination (SVM-RFE), have been used and hold promise for early detection of AD and the prediction of AD progression (Rathore et al., 2017).In order to apply such machine learning algorithms, appropriate architectural design or pre-processing steps must be predefined (Lu and Weng, 2007). Classification studies using machine learning generally require four steps: feature extraction, feature selection, dimensionality reduction, and feature-based classification algorithm selection. These procedures require specialized knowledge and multiple stages of optimization, which may be time-consuming. Reproducibility of these approaches has been an issue (Samper-Gonzalez et al., 2018). For example, in the feature selection process, AD-related features are chosen from various neuroimaging modalities to derive more informative combinatorial measures, which may include mean subcortical volumes, gray matter densities, cortical thickness, brain glucose metabolism, and cerebral amyloid-β accumulation in regions of interest (ROIs), such as the hippocampus (Riedel et al., 2018).In order to overcome these difficulties, deep learning, an emerging area of machine learning research that uses raw neuroimaging data to generate features through “on-the-fly” learning, is attracting considerable attention in the field of large-scale, high-dimensional medical imaging analysis (Plis et al., 2014). Deep learning methods, such as convolutional neural networks (CNN), have been shown to outperform existing machine learning methods (Lecun et al., 2015).We systematically reviewed publications where deep learning approaches and neuroimaging data were used for the early detection of AD and the prediction of AD progression. A PubMed and Google Scholar search was used to identify deep learning papers on AD published between January 2013 and July 2018. The papers were reviewed and evaluated, classified by algorithms and neuroimaging types, and the findings were summarized. In addition, we discuss challenges and implications for the application of deep learning to AD research.
Deep Learning Methods
Deep learning is a subset of machine learning (Lecun et al., 2015), meaning that it learns features through a hierarchical learning process (Bengio, 2009). Deep learning methods for classification or prediction have been applied in various fields, including computer vision (Ciregan et al., 2012; Krizhevsky et al., 2012; Farabet et al., 2013) and natural language processing (Hinton et al., 2012; Mikolov et al., 2013), both of which demonstrate breakthroughs in performance (Boureau et al., 2010; Russakovsky et al., 2015). Because deep learning methods have been reviewed extensively in recent years (Bengio, 2013; Bengio et al., 2013; Schmidhuber, 2015), we focus here on basic concepts of Artificial Neural Networks (ANN) that underlie deep learning (Hinton and Salakhutdinov, 2006). We also discuss architectural layouts of deep learning that have been applied to the task of AD classification and prognostic prediction. ANN is a network of interconnected processing units called artificial neurons that were modeled (Mcculloch and Pitts, 1943) and developed with the concept of Perceptron (Rosenblatt, 1957, 1958), Group Method of Data Handling (GMDH) (Ivakhnenko and Lapa, 1965; Ivakhnenko, 1968, 1971), and the Neocognitron (Fukushima, 1979, 1980). Efficient error functions and gradient computing methods were discussed in these seminal publications, spurred by the demonstrated limitation of the single layer perceptron, which can learn only linearly separable patterns (Minsky and Papert, 1969). Further, the back-propagation procedure, which uses gradient descent, was developed and applied to minimize the error function (Werbos, 1982, 2006; Rumelhart et al., 1986; Lecun et al., 1988).
Gradient Computation
The back-propagation procedure is used to calculate the error between the network output and the expected output. The back propagation calculates the gap repeatedly, changing weights and stopping the calculation when the gap is no longer updated (Rumelhart et al., 1986; Bishop, 1995; Ripley and Hjort, 1996; Schalkoff, 1997). Figure 1 illustrates the process of the neural network made by multilayer perceptron. After the initial error value is calculated from the given random weight by the least squares method, the weights are updated until the differential value becomes 0. For example, the w31 in Figure 1 is updated by the following formula:

The ErrorYout is the sum of error yo1 and error yo2. yt1, yt2 are constants that are known through the given data. The partial derivative of ErrorYout with respect to w31 can be calculated by the chain rule as follows.

Likewise, w11 in the hidden layer is updated by the chain rule as follows.

Detailed calculation of the weights in the backpropagation is described in Supplement 1.
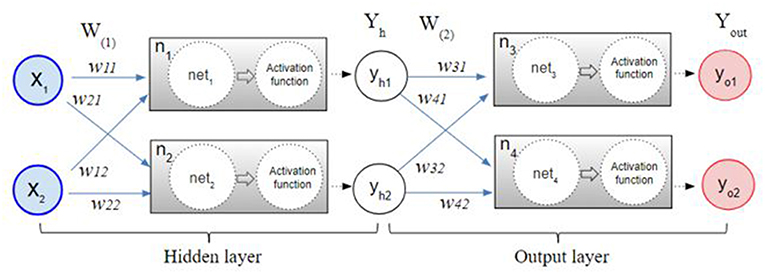
Figure 1. The multilayer perceptron procedure. After the initial error value is calculated from the given random weight by the least squares method, the weights are updated by a back-propagation algorithm until the differential value becomes 0.
Modern Practical Deep Neural Networks
As the back-propagation uses a gradient descent method to calculate the weights of each layer going backwards from the output layer, a vanishing gradient problem occurs as the layer is stacked, where the differential value becomes 0 before finding the optimum value. As shown in Figure 2A, when the sigmoid is differentiated, the maximum value is 0.25, which becomes closer to 0 when it continues to multiply. This is called a vanishing gradient issue, a major obstacle of the deep neural network. Considerable research has addressed the challenge of the vanishing gradient (Goodfellow et al., 2016). One of the accomplishments of such an effort is to replace the sigmoid function, an activation function, with several other functions, such as the hyperbolic tangent function, ReLu, and Softplus (Nair and Hinton, 2010; Glorot et al., 2011). The hyperbolic tangent (tanh, Figure 2B) function expands the range of derivative values of the sigmoid. The ReLu function (Figure 2C), the most used activation function, replaces a value with 0 when the value is <0 and uses the value if the value is >0. As the derivative becomes 1, when the value is larger than 0, it becomes possible to adjust the weights without disappearing up to the first layer through the stacked hidden layers. This simple method allows building multiple layers and accelerates the development of deep learning. The Softplus function (Figure 2D) replaces the ReLu function with a gradual descent method when ReLu becomes zero.
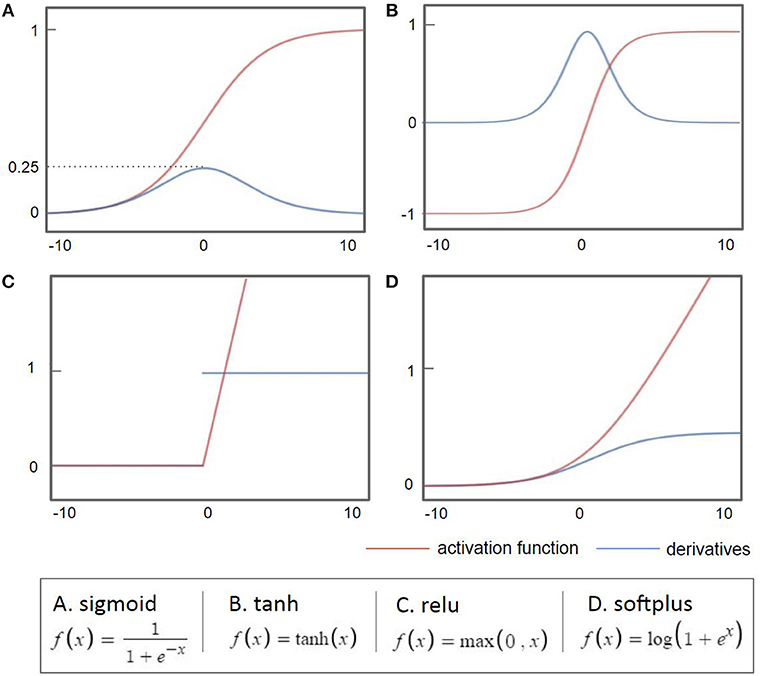
Figure 2. Common activation functions used in deep learning (red) and their derivatives (blue). When the sigmoid is differentiated, the maximum value is 0.25, which becomes closer to 0 when it continues to multiply.
While a gradient descent method is used to calculate the weights accurately, it usually requires a large amount of computation time because all of the data needs to be differentiated at each update. Thus, in addition to the activation function, advanced gradient descent methods have been developed to solve speed and accuracy issues. For example, Stochastic Gradient Descent (SGD) uses a subset that is randomly extracted from the entire data for faster and more frequent updates (Bottou, 2010), and it has been extended to Momentum SGD (Sutskever et al., 2013). Currently, one of the most popular gradient descent method is Adaptive Moment Estimation (Adam). Detailed calculation of the optimization methods is described in Supplement 2.
Architectures of Deep Learning
Overfitting has also played a major role in the history of deep learning (Schmidhuber, 2015), with efforts being made to solve it at the architectural level. The Restricted Boltzmann Machine (RBM) was one of the first models developed to overcome the overfitting problem (Hinton and Salakhutdinov, 2006). Stacking the RBMs resulted in building deeper structures known as the Deep Boltzmann Machine (DBM) (Salakhutdinov and Larochelle, 2010). The Deep Belief Network (DBN) is a supervised learning method used to connect unsupervised features by extracting data from each stacked layer (Hinton et al., 2006). DBN was found to have a superior performance to other models and is one of the reasons that deep learning has gained popularity (Bengio, 2009). While DBN solves the overfitting problem by reducing the weight initialization using RBM, CNN efficiently reduces the number of model parameters by inserting convolution and pooling layers that lead to a reduction in complexity. Because of its effectiveness, when given enough data, CNN is widely used in the field of visual recognition. Figure 3 shows the structures of RBM, DBM, DBN, CNN, Auto-Encoders (AE), sparse AE, and stacked AE, respectively. Auto-Encoders (AE) are an unsupervised learning method that make the output value approximate to the input value by using the back-propagation and SGD (Hinton and Zemel, 1994). AE engages the dimensional reduction, but it is difficult to train due to the vanishing gradient issue. Sparse AE has solved this issue by allowing for only a small number of the hidden units (Makhzani and Frey, 2015). Stacked AE stacks sparse AE like DBN.
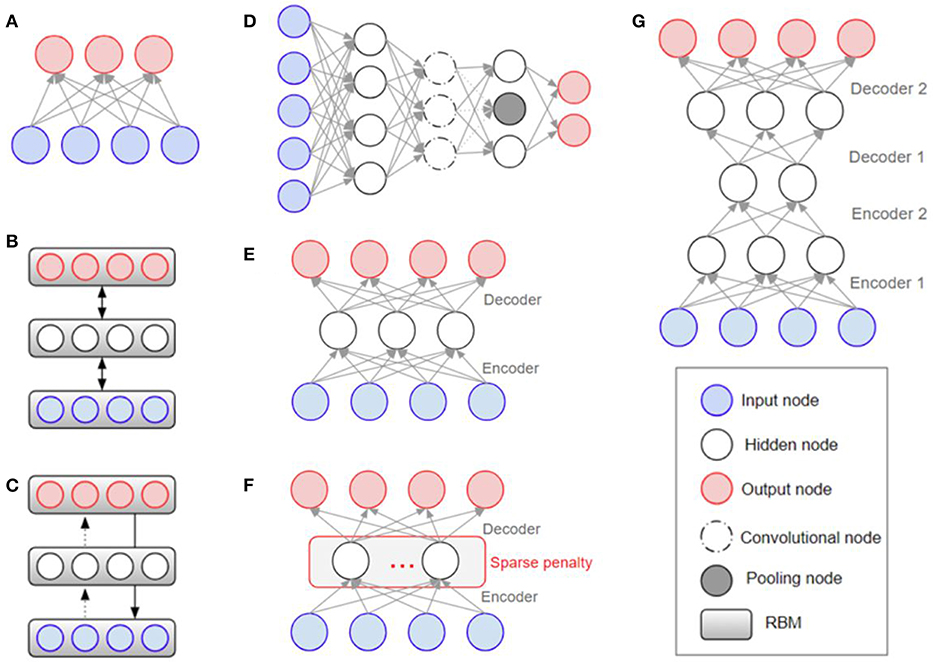
Figure 3. Architectural structures in deep learning: (A)** RBM (Hinton and Salakhutdinov, 2006) (B) DBM (Salakhutdinov and Larochelle, 2010) (C) DBN (Bengio, 2009) (D) CNN (Krizhevsky et al., 2012) (E) AE (Fukushima, 1975; Krizhevsky and Hinton, 2011) (F) Sparse AE (Vincent et al., 2008, 2010) (G) Stacked AE (Larochelle et al., 2007; Makhzani and Frey, 2015). RBM, Restricted Boltzmann Machine; DBM, Deep Boltzmann Machine; DBN, Deep Belief Network; CNN, Convolutional Neural Network; AE, Auto-Encoders.
DNN, RBM, DBM, DBN, AE, Sparse AE, and Stacked AE are deep learning methods that have been used for Alzheimer’s disease diagnostic classification to date (see Table 1 for the definition of acronyms). Each approach has been developed to classify AD patients from cognitively normal controls (CN) or mild cognitive impairment (MCI), which is the prodromal stage of AD. Each approach is used to predict the conversion of MCI to AD using multi-modal neuroimaging data. In this paper, when deep learning is used together with traditional machine learning methods, i.e., SVM as a classifier, it is referred to as a “hybrid method.”
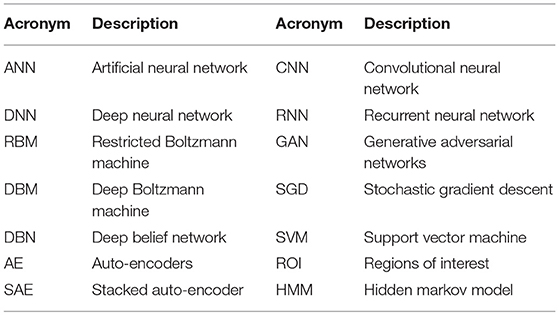
Table 1. Definition of acronyms.
Materials and Methods
We conducted a systematic review on previous studies that used deep learning approaches for diagnostic classification of AD with multimodal neuroimaging data. The search strategy is outlined in detail using the PRISMA flow diagram (Moher et al., 2009) in Figure 4.
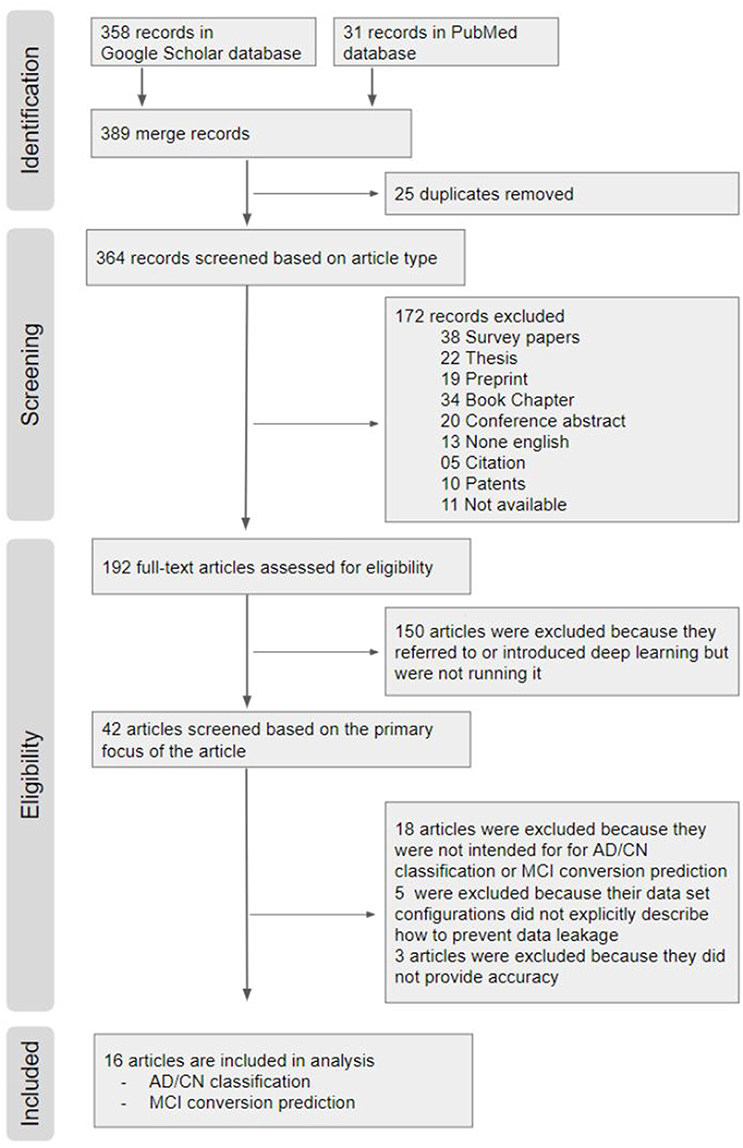
Figure 4. PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) Flow Chart. From a total of 389 hits on Google scholar and PubMed search, 16 articles were included in the systematic review.
Identification
From a total of 389 hits on Google scholar and PubMed search, 16 articles were included in the systematic review.Google Scholar: We searched using the following key words and yielded 358 results (“Alzheimer disease” OR “Alzheimer’s disease”), (“deep learning” OR “deep neural network” OR “CNN” OR “CNN” OR “Autoencoder” OR “DBN” OR “RBM”), (“Neuroimaging” OR “MRI” OR “multimodal”).
PubMed: The keywords used in the Google Scholar search were reused for the search in PubMed, and yielded 31 search results (“Alzheimer disease” OR “Alzheimer’s disease”) AND (“deep learning” OR “deep neural network” OR “CNN” OR “recurrent neural network” OR “Auto-Encoder” OR “Auto Encoder” OR “RBM” OR “DBN” OR “Generative Adversarial Network” OR “Reinforcement Learning” OR “Long Short Term Memory” OR “Gated Recurrent Units”) AND (“Neuroimaging” OR “MRI” OR “multimodal”).
Among the 389 relevant records, 25 overlapping records were removed.
Screening Based on Article Type
We first excluded 38 survey papers, 22 theses, 19 Preprint, 34 book chapters, 20 conference abstract, 13 none English papers, 5 citations, and 10 patents. We also excluded 11 papers of which the full text was not accessible. The remaining 192 articles were downloaded for review.
Eligibility Screening
Out of the 192 publications retrieved, 150 articles were excluded because the authors only introduced or mentioned deep learning but did not use it. Out of the 42 remaining publications, (1) 18 articles were excluded because they did not perform deep learning approaches for AD classification and/or prediction of MCI to AD conversion; (2) 5 articles were excluded because their neuroimaging data were not explicitly described; and (3) 3 articles were excluded because performance results were not provided. The remaining 16 papers were included in this review for AD classification and/or prediction of MCI to AD conversion. All of the final selected and compared papers used ADNI data in common.
Results
From the 16 papers included in this review, Table 2 provides the top results of diagnostic classification and/or prediction of MCI to AD conversion. We compared only binary classification results. Accuracy is a measure used consistently in the 16 publications. However, it is only one metric of the performance characteristics of an algorithm. The group composition, sample sizes, and number of scans analyzed are also noted together because accuracy is sensitive to unbalanced distributions. Table S1 shows the full results sorted according to the performance accuracy as well as the number of subjects, the deep learning approach, and the neuroimaging type used in each paper.
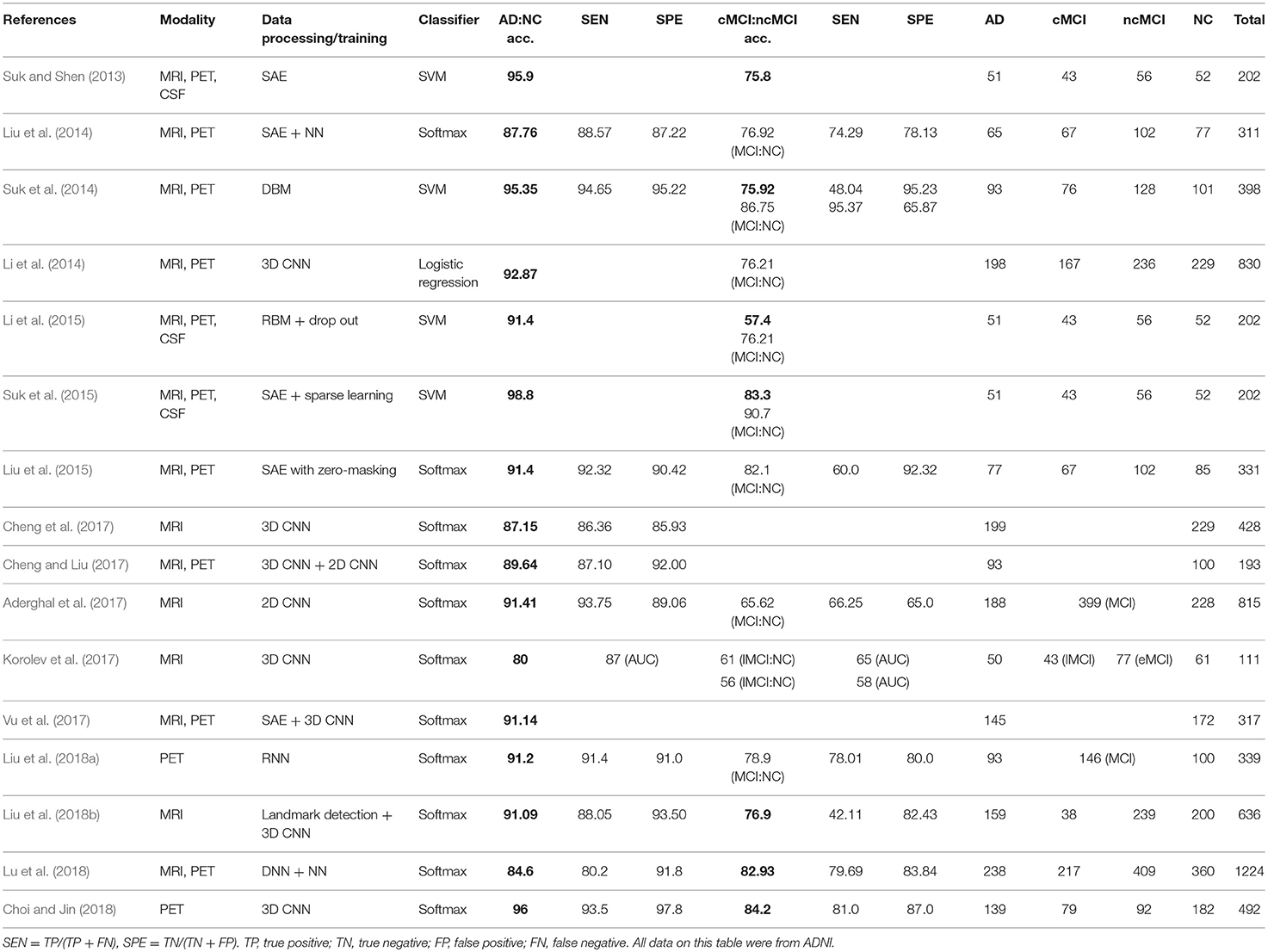
Table 2. Summary of 16 previous studies to systematically be reviewed.
Deep Learning for Feature Selection From Neuroimaging Data
Multimodal neuroimaging data have been used to identify structural and molecular/functional biomarkers for AD. It has been shown that volumes or cortical thicknesses in pre-selected AD-specific regions, such as the hippocampus and entorhinal cortex, could be used as features to enhance the classification accuracy in machine learning. Deep learning approaches have been used to select features from neuroimaging data.As shown in Figure 5, 4 studies have used hybrid methods that combine deep learning for feature selection from neuroimaging data and traditional machine learning, such as the SVM as a classifier. Suk and Shen (2013) used a stacked auto-encoder (SAE) to construct an augmented feature vector by concatenating the original features with outputs of the top hidden layer of the representative SAEs. Then, they used a multi-kernel SVM for classification to show 95.9% accuracy for AD/CN classification and 75.8% prediction accuracy of MCI to AD conversion. These methods successfully tuned the input data for the SVM classifier. However, SAE as a classifier (Suk et al., 2015) yielded 89.9% accuracy for AD/CN classification and 60.2% accuracy for prediction of MCI to AD conversion. Later Suk et al. (2015) extended the work to develop a two-step learning scheme: greedy layer-wise pre-training and fine-tuning in deep learning. The same authors further extended their work to use the DBM to find latent hierarchical feature representations by combining heterogeneous modalities during the feature representation learning (Suk et al., 2014). They obtained 95.35% accuracy for AD/CN classification and 74.58% prediction accuracy of MCI to AD conversion. In addition, the authors initialized SAE parameters with target-unrelated samples and tuned the optimal parameters with target-related samples to have 98.8% accuracy for AD/CN classification and 83.7% accuracy for prediction of MCI to AD conversion (Suk et al., 2015). Li et al. (2015) used the RBM with a dropout technique to reduce overfitting in deep learning and SVM as a classifier, which produced 91.4% accuracy for AD/CN classification and 57.4% prediction accuracy of MCI to AD conversion.
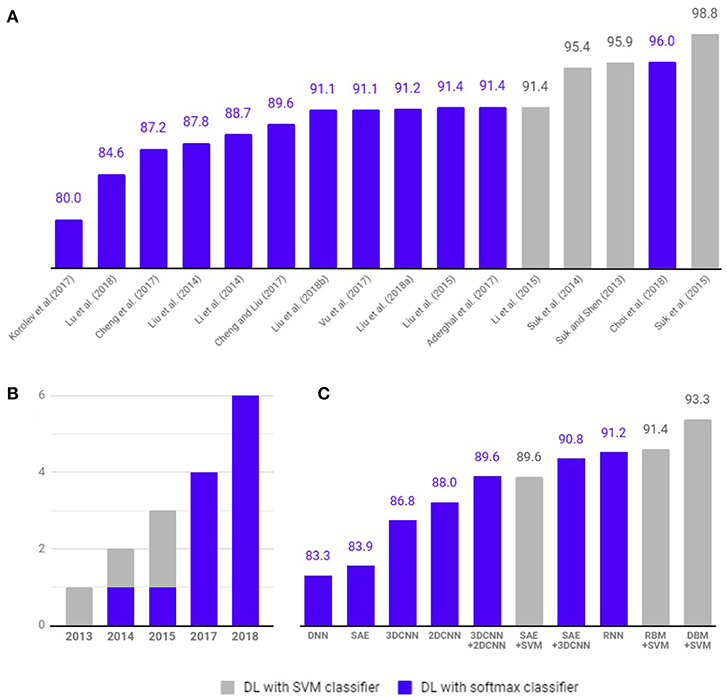
Figure 5. Comparison of diagnostic classification accuracy of pure deep learning and hybrid approach. Four studies (gray) have used hybrid methods that combine deep learning for feature selection from neuroimaging data and traditional machine learning, such as the SVM as a classifier. Twelve studies (blue) have used deep learning method with softmax classifier for diagnostic classification and/or prediction of MCI to AD conversion. (A) Accuracy comparison between articles. (B) Number of studies published per year. (C) Average classification accuracy of each methods.
Deep Learning for Diagnostic Classification and Prognostic Prediction
To select optimal features from multimodal neuroimaging data for diagnostic classification, we usually need several pre-processing steps, such as neuroimaging registration and feature extraction, which greatly affect the classification performance. However, deep learning approaches have been applied to AD diagnostic classification using original neuroimaging data without any feature selection procedures.
As shown in Figure 5, 12 studies have used only deep learning for diagnostic classification and/or prediction of MCI to AD conversion. Liu et al. (2014) used stacked sparse auto-encoders (SAEs) and a softmax regression layer and showed 87.8% accuracy for AD/CN classification. Liu et al. (2015) used SAE and a softmax logistic regressor as well as a zero-mask strategy for data fusion to extract complementary information from multimodal neuroimaging data (Ngiam et al., 2011), where one of the modalities is randomly hidden by replacing the input values with zero to converge different types of image data for SAE. Here, the deep learning algorithm improved accuracy for AD/CN classification by 91.4%. Recently, Lu et al. (2018) used SAE for pre-training and DNN in the last step, which achieved an AD/CN classification accuracy of 84.6% and an MCI conversion prediction accuracy of 82.93%. CNN, which has shown remarkable performance in the field of image recognition, has also been used for the diagnostic classification of AD with multimodal neuroimaging data. Cheng et al. (2017) used image patches to transform the local images into high-level features from the original MRI images for the 3D-CNN and yielded 87.2% accuracy for AD/CN classification. They improved the accuracy to 89.6% by running two 3D-CNNs on neuroimage patches extracted from MRI and PET separately and by combining their results to run 2D CNN (Cheng and Liu, 2017). Korolev et al. (2017) applied two different 3D CNN approaches [plain (VoxCNN) and residual neural networks (ResNet)] and reported 80% accuracy for AD/CN classification, which was the first study that the manual feature extraction step was unnecessary. Aderghal et al. (2017) captured 2D slices from the hippocampal region in the axial, sagittal, and coronal directions and applied 2D CNN to show 85.9% accuracy for AD/CN classification. Liu et al. (2018b) selected discriminative patches from MR images based on AD-related anatomical landmarks identified by a data-driven learning approach and ran 3D CNN on them. This approach used three independent data sets (ADNI-1 as training, ADNI-2 and MIRIAD as testing) to yield relatively high accuracies of 91.09 and 92.75% for AD/CN classification from ADNI-2 and MIRIAD, respectively, and an MCI conversion prediction accuracy of 76.9% from ADNI-2. Li et al. (2014) trained 3D CNN models on subjects with both MRI and PET scans to encode the non-linear relationship between MRI and PET images and then used the trained network to estimate the PET patterns for subjects with only MRI data. This study obtained an AD/CN classification accuracy of 92.87% and an MCI conversion prediction accuracy of 72.44%. Vu et al. (2017) applied SAE and 3D CNN to subjects with MRI and FDG PET scans to yield an AD/CN classification accuracy of 91.1%. Liu et al. (2018a) decomposed 3D PET images into a sequence of 2D slices and used a combination of 2D CNN and RNNs to learn the intra-slice and inter-slice features for classification, respectively. The approach yielded AD/CN classification accuracy of 91.2%. If the data is imbalanced, the chance of misdiagnosis increases and sensitivity decreases. For example, in Suk et al. (2014) there were 76 cMCI and 128 ncMCI subjects and the obtained sensitivity of 48.04% was low. Similarly, Liu et al. (2018b) included 38 cMCI and 239 ncMCI subjects and had a low sensitivity of 42.11%. Recently Choi and Jin (2018) reported the first use of 3D CNN models to multimodal PET images [FDG PET and [18F]florbetapir PET] and obtained 96.0% accuracy for AD/CN classification and 84.2% accuracy for the prediction of MCI to AD conversion.
Performance Comparison by Types of Neuroimaging Techniques
In order to improve the performance for AD/CN classification and for the prediction of MCI to AD conversion, multimodal neuroimaging data such as MRI and PET have commonly been used in deep learning: MRI for brain structural atrophy, amyloid PET for brain amyloid-β accumulation, and FDG-PET for brain glucose metabolism. MRI scans were used in 13 studies, FDG-PET scans in 10, both MRI and FDG-PET scans in 12, and both amyloid PET and FDG-PET scans in 1. The performance in AD/CN classification and/or prediction of MCI to AD conversion yielded better results in PET data compared to MRI. Two or more multimodal neuroimaging data types produced higher accuracies than a single neuroimaging technique. Figure 6 shows the results of the performance comparison by types of neuroimaging techniques.
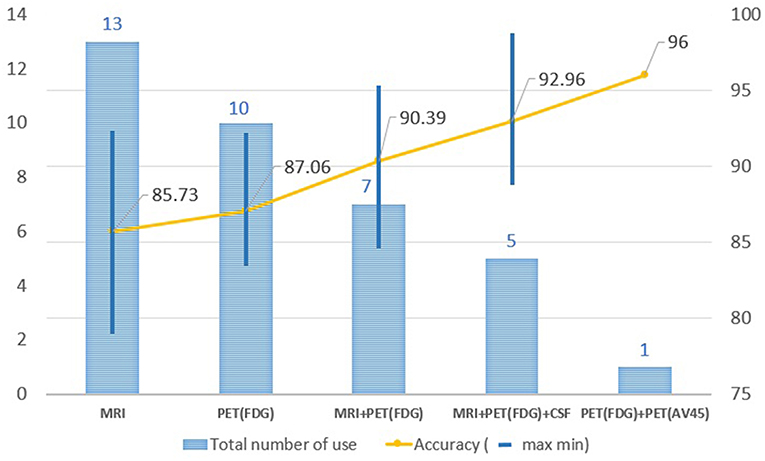
Figure 6. Changes in accuracy by types of image resource. MRI scans were used in 13 studies, FDG-PET scans in 10, both MRI and FDG-PET scans in 12, and both amyloid PET and FDG-PET scans in 1. The performance in AD/CN classification yielded better results in PET data compared to MRI. Two or more multimodal neuroimaging data types produced higher accuracies than a single neuroimaging technique.
Performance Comparison by Deep Learning Algorithms
Deep learning approaches require massive amounts of data to achieve the desired levels of performance accuracy. In currently limited neuroimaging data, the hybrid methods that combine traditional machine learning methods for diagnostic classification with deep learning approaches for feature extraction yielded better performance and can be a good alternative to handle the limited data. Here, an auto-encoder (AE) was used to decode the original image values, making them similar to the original image, which it then included as input, thereby effectively utilizing the limited neuroimaging data. Although hybrid approaches have yielded relatively good results, they do not take full advantage of deep learning, which automatically extracts features from large amounts of neuroimaging data. The most commonly used deep learning method in computer vision studies is the CNN, which specializes in extracting characteristics from images. Recently, 3D CNN models using multimodal PET images [FDG-PET and [18F]florbetapir PET] showed better performance for AD/CN classification and for the prediction of MCI to AD conversion.
Discussion
Effective and accurate diagnosis of Alzheimer’s disease (AD) is important for initiation of effective treatment. Particularly, early diagnosis of AD plays a significant role in therapeutic development and ultimately for effective patient care. In this study, we performed a systematic review of deep learning approaches based on neuroimaging data for diagnostic classification of AD. We analyzed 16 articles published between 2013 and 2018 and classified them according to deep learning algorithms and neuroimaging types. Among 16 papers, 4 studies used a hybrid method to combine deep learning and traditional machine learning approaches as a classifier, and 12 studies used only deep learning approaches. In a limited available neuroimaging data set, hybrid methods have produced accuracies of up to 98.8% for AD classification and 83.7% for prediction of conversion from MCI to AD. Deep learning approaches have yielded accuracies of up to 96.0% for AD classification and 84.2% for MCI conversion prediction. While it is a source of concern when experiments obtain a high accuracy using small amounts of data, especially if the method is vulnerable to overfitting, the highest accuracy of 98.8% was due to the SAE procedure, whereas the 96% accuracy was due to the amyloid PET scan, which included pathophysiological information regarding AD. The highest accuracy for the AD classification was 87% when 3DCNN was applied from the MRI without the feature extraction step (Cheng et al., 2017). Therefore, two or more multimodal neuroimaging data types have been shown to produce higher accuracies than a single neuroimaging type.
In traditional machine learning, well-defined features influence performance results. However, the greater the complexity of the data, the more difficult it is to select optimal features. Deep learning identifies optimal features automatically from the data (i.e., the classifier trained by deep learning finds features that have an impact on diagnostic classification without human intervention). Because of its ease-of-use and better performance, deep learning has been used increasingly for medical image analysis. The number of studies of AD using CNN, which show better performance in image recognition among deep learning algorithms, has increased drastically since 2015. This is consistent with a previous survey showing that the use of deep learning for lesion classification, detection, and segmentation has also increased rapidly since 2015 (Litjens et al., 2017).
Recent trends in the use of deep learning are aimed at faster analysis with better accuracy than human practitioners. Google’s well-known study for the diagnostic classification of diabetic retinopathy (Gulshan et al., 2016) showed classification performance that goes well beyond that of a skilled professional. The diagnostic classification by deep learning needs to show consistent performance under various conditions, and the predicted classifier should be interpretable. In order for diagnostic classification and prognostic prediction using deep learning to reach readiness for real world clinical applicability, several issues need to be addressed, as discuss below.
Transparency
Traditional machine learning approaches may require expert involvement in preprocessing steps for feature extraction and selection from images. However, since deep learning does not require human intervention but instead extracts features directly from the input images, the data preprocessing procedure is not routinely necessary, allowing flexibility in the extraction of properties based on various data-driven inputs. Therefore, deep learning can create a good, qualified model at each time of the run. The flexibility has shown deep learning to achieve a better performance than other traditional machine learning that relies on preprocessing (Bengio, 2013). However, this aspect of deep learning necessarily brings uncertainty over which features would be extracted at every epoch, and unless there is a special design for the feature, it is very difficult to show which specific features were extracted within the networks (Goodfellow et al., 2016). Due to the complexity of the deep learning algorithm, which has multiple hidden layers, it is also difficult to determine how those selected features lead to a conclusion and to the relative importance of specific features or subclasses of features. This is a major limitation for mechanistic studies where understanding the informativeness of specific features is desirable for model building. These uncertainties and complexities tend to make the process of achieving high accuracy opaque and also make it more difficult to correct any biases that arise from a given data set. This lack of clarity also limits the applicability of obtained results to other use cases.
The issue of transparency is linked to the clarity of the results from machine learning and is not a problem limited to deep learning (Kononenko, 2001). Despite the simple principle, the complexity of the algorithm makes it difficult to describe mathematically. When one perceptron advances to a neural network by adding more hidden layers, it becomes even more difficult to explain why a particular prediction was made. AD classification based on 3D multimodal medical images with deep learning involves non-linear convolutional layers and pooling that have different dimensionality from the source data, making it very difficult to interpret the relative importance of discriminating features in original data space. This is a fundamental challenge in view of the importance of anatomy in the interpretation of medical images, such as MRI or PET scans. The more advanced algorithm generates plausible results, but the mathematical background is difficult to explain, although the output for diagnostic classification should be clear and understandable.
Reproducibility
Deep learning performance is sensitive to the random numbers generated at the start of training, and hyper-parameters, such as learning rates, batch sizes, weight decay, momentum, and dropout probabilities, may be tuned by practitioners (Hutson, 2018). To produce the same experimental result, it is important to set the same random seeds on multiple levels. It is also important to maintain the same code bases (Vaswani et al., 2018), even though the hyper-parameters and random seeds were not, in most cases, provided in our study. The uncertainty of the configuration and the randomness involved in the training procedure may make it difficult to reproduce the study and achieve the same results.
When the available neuroimaging data is limited, careful consideration at the architectural level is needed to avoid the issues of overfitting and reproducibility. Data leakage in machine learning (Smialowski et al., 2009) occurs when the data set framework is designed incorrectly, resulting in a model that uses inessential additional information for classification. In the case of diagnostic classification for the progressive and irreversible Alzheimer’s disease, all subsequent MRI images should be labeled as belonging to a patient with Alzheimer’s disease. Once the brain structure of the patient is shared by both the training and testing sets, the morphological features of the patient’s brain greatly influence the classification decision, rather than the biomarkers of dementia. In the present study, articles were excluded from the review if the data set configurations did not explicitly describe how to prevent data leakage (Figure 4).
Future studies ultimately need to replicate key findings from deep learning on entirely independent data sets. This is now widely recognized in genetics (König, 2011; Bush and Moore, 2012) and other fields but has been slow to penetrate deep learning studies employing neuroimaging data. Hopefully the emerging open ecology of medical research data, especially in the AD and related disorders field (Toga et al., 2016; Reas, 2018), will provide a basis to remediate this problem.
Outlook and Future Direction
Deep Learning algorithms and applications continue to evolve, producing the best performance in closed-ended cases, such as image recognition (Marcus, 2018). It works particularly well when inference is valid, i.e., the training and test environments are similar. This is especially true in the study of AD when using neuroimages (Litjens et al., 2017). One weakness of deep learning is that it is difficult to modify potential bias in the network when the complexity is too great to guarantee transparency and reproducibility. The issue may be solved through the accumulation of large-scale neuroimaging data and by studying the relationships between deep learning and features. Disclosing the parameters used to obtain the results and mean values from sufficient experimentations can mitigate the issue of reproducibility.
Not all problems can be solved with deep learning. Deep learning that extracts attributes directly from the input data without preprocessing for feature selection has difficulty integrating different formats of data as an input, such as neuroimaging and genetic data. Because the adjustment of weights for the input data is performed automatically within a closed network, adding additional input data into the closed network causes confusion and ambiguity. A hybrid approach, however, puts the additional information into machine learning parts and the neuroimages into deep learning parts before combining the two results.
Progress will be made in deep learning by overcoming these issues while presenting problem-specific solutions. As more and more data are acquired, research using deep learning will become more impactful. The expansion of 2D CNN into 3D CNN is important, especially in the study of AD, which deals with multimodal neuroimages. In addition, Generative Adversarial Networks (GAN) (Goodfellow et al., 2014) may be applicable for generating synthetic medical images for data augmentation. Furthermore, reinforcement learning (Sutton and Barto, 2018), a form of learning that adapts to changes in data as it makes its own decision based on the environment, may also demonstrate applicability in the field of medicine.
AD research using deep learning is still evolving to achieve better performance and transparency. As multimodal neuroimaging data and computer resources grow rapidly, research on the diagnostic classification of AD using deep learning is shifting toward a model that uses only deep learning algorithms rather than hybrid methods, although methods need to be developed to integrate completely different formats of data in a deep learning network.
이 글은 2019년 8월 20일, Frontiers in Aging Neuroscience에 게재된 Taeho Jo et al. Deep learning in Alzheimer’s disease: diagnostic classification and prognostic prediction using neuroimaging data 논문을 옮긴 것입니다.
논문 인용 하기
Jo, Taeho, Kwangsik Nho, and Andrew J. Saykin. "Deep learning in Alzheimer's disease: diagnostic classification and prognostic prediction using neuroimaging data." Frontiers in aging neuroscience 11 (2019): 220.
